절차형 SQL
개요
Programming Language for SQL
일반 개발 언어처럼 절차지향적인 프로그램 작성이 가능하도록 만든 것이 절차형 sql이다.
연속 실행, 분기처리가 가능해진다.
크게 3가지 종류가 있다.
장점
일단 위에서 말했듯이 절차형으로 작성하여 세밀한 조작이 가능해진다.
어떤 데이터를 넣을 때는 어떻게 조작을 해서 넣는다던가, 어떤 건 안 넣는다던가..
여기에 한번에 만들어서 쿼리를 날리니, 일일히 쿼리를 날리는 것보다 트래픽이 줄어든다는 것도 이점이다.
구조
블록 구조로 이뤄져있다.
이것은 한번에 서버로 보내지기 때문에 네트워크 트래픽이 감소된다.
DECLARE
BEGIN
EXCEPTION
END
이런 식의 구조를 가진다.
본격적으로 시작하기 이전에 필요한 변수와 인수 설정 이후 시작.
그러다 에러가 발생한다면 예외처리를 해줄 수 있고, 끝을낸다.
그럼 본격적으로 절차형 sql을 사용하는 객체들을 보자
프로시저
첫번째는 프로시저.
--프로시저 만들기
CREATE OR REPLACE PROCEDURE SP_INSERT_TB_POPLTN_CTPRVN
(IN_STD_YM IN TB_POPLTN.STD_YM%TYPE) -- 입력 값 정의
-- declare. is로 변수를 나타낸다.
IS
V_CTPRVN_CD TB_POPLTN_CTPRVN.CTPRVN_CD%TYPE;
V_CTPRVN_NM TB_POPLTN_CTPRVN.CTPRVN_NM%TYPE;
V_STD_YM TB_POPLTN_CTPRVN.STD_YM%TYPE;
V_POPLTN_SE_CD TB_POPLTN_CTPRVN.POPLTN_SE_CD%TYPE;
V_AGRDE_SE_CD TB_POPLTN_CTPRVN.AGRDE_SE_CD%TYPE;
V_POPLTN_CNT TB_POPLTN_CTPRVN.POPLTN_CNT%TYPE;
-- cursor is는 커서라는 뷰같은 놈을 만든다.
CURSOR SELECT_TB_POPLTN IS
SELECT SUBSTR(A.ADSTRD_CD , 1, 2) AS CTPRVN_CD
, (SELECT L.ADRES_CL_NM
FROM TB_ADRES_CL L
WHERE L.ADRES_CL_CD = SUBSTR(A.ADSTRD_CD , 1, 2)
AND L.ADRES_CL_SE_CD = 'ACS001'
) AS CTPRVN_NM
, A.STD_YM
, A.POPLTN_SE_CD
, A.AGRDE_SE_CD
, SUM(A.POPLTN_CNT ) AS POPLTN_CNT
FROM TB_POPLTN A
WHERE 1=1
GROUP BY SUBSTR(A.ADSTRD_CD , 1, 2), A.STD_YM
, A.POPLTN_SE_CD
, A.AGRDE_SE_CD
ORDER BY SUBSTR(A.ADSTRD_CD , 1, 2)
, A.STD_YM
, A.POPLTN_SE_CD
, A.AGRDE_SE_CD
;
-- begin으로 본격 로직이 시작된다.
BEGIN
OPEN SELECT_TB_POPLTN; -- 커서를 연다.
DBMS_OUTPUT.PUT_LINE('------------------------------');
LOOP -- 반복문
FETCH SELECT_TB_POPLTN -- 한 행씩 가져온다.
INTO
V_CTPRVN_CD
, V_CTPRVN_NM
, V_STD_YM
, V_POPLTN_SE_CD
, V_AGRDE_SE_CD
, V_POPLTN_CNT;
-- 각 변수에 한 행의 값이 들어감
-- 행에 아무것도 없다면, 즉 다 돌았으면 exit
EXIT WHEN SELECT_TB_POPLTN%NOTFOUND;
-- 로그 출력
DBMS_OUTPUT.PUT_LINE('V_CTPRVN_CD :'||'['|| V_CTPRVN_CD ||']');
DBMS_OUTPUT.PUT_LINE('V_CTPRVN_NM :'||'['|| V_CTPRVN_NM ||']');
DBMS_OUTPUT.PUT_LINE('V_STD_YM :'||'['|| V_STD_YM ||']');
DBMS_OUTPUT.PUT_LINE('V_POPLTN_SE_CD:'||'['|| V_POPLTN_SE_CD||']');
DBMS_OUTPUT.PUT_LINE('V_AGRDE_SE_CD :'||'['|| V_AGRDE_SE_CD ||']');
DBMS_OUTPUT.PUT_LINE('V_POPLTN_CNT :'||'['|| V_POPLTN_CNT ||']');
--IF문.
IF V_STD_YM = IN_STD_YM THEN
INSERT INTO TB_POPLTN_CTPRVN
VALUES ( V_CTPRVN_CD
, V_CTPRVN_NM
, V_STD_YM
, V_POPLTN_SE_CD
, V_AGRDE_SE_CD
, V_POPLTN_CNT
);
END IF; --IF문 종료
END LOOP; -- 반복문 종료
CLOSE SELECT_TB_POPLTN; -- open한 커서도 닫아준다.
COMMIT;
DBMS_OUTPUT.PUT_LINE('------------------------------');
END SP_INSERT_TB_POPLTN_CTPRVN; --begin은 end로 끝난다. 프로시저 정의 완료
/
엄청 길다.
is를 통해 변수를 선언하고, 사용할 테이블을 커서로 지정한다.
이후에는 반복문을 돌면서 한 행씩 가져오다가 조건에 충족하는 놈들만 insert를 시킨다.
조건은 입력값과 같은 년도인지이니까, 내가 원하는 년도에 해당하는 데이터가 들어간 테이블이 만들어져야 한다.
책에서 sqlplus에서 한다던데 왜 그런 걸까 궁금했다.
이거 dbeaver에서 실행하려니 ;가 delimeter로 인식돼서 그런지 계속 막혔다.
원하는 스크립트를 딱 선택해서 전체 실행을 하던가, 해야 한다.
아니면 커넥션에 가서 gui툴로 프로시저를 만드는 것을 선택하고 거기에 문법을 작성하는 방법도 있다.
그리고, dbeaver에서 프로시저를 호출하려면 call을 써야 한다.
뭐 이렇게 저마다 다르냐?
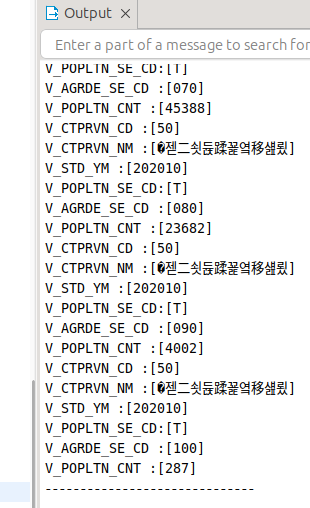
로그가 표시되는 것이 보인다.
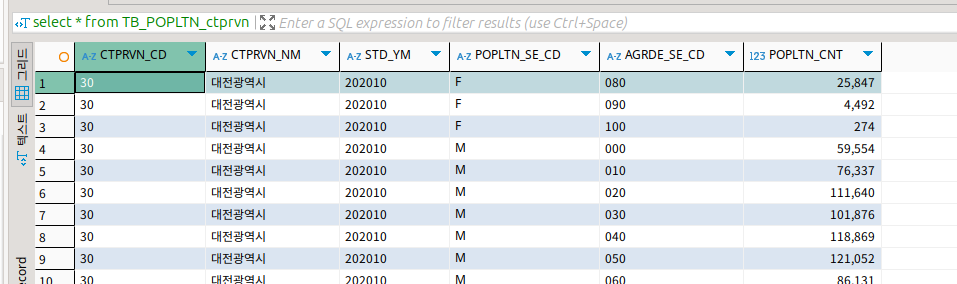
데이터도 성공적으로 들어갔다.
괜히 책에서 sqlplus에서 하는 게 아닌 것 같다..
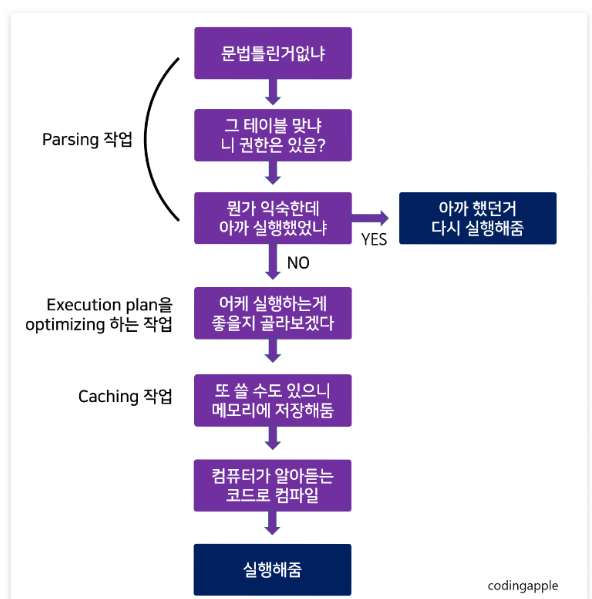
프로시저는 이러한 이점이 있다.
원래는 한번의 sql 쿼리가 실행되기 위해 이런 작업을 거치는데, 이 중에 상당한 부분을 미리 해결해주는 것이다.
그리고 실행 로직이 디비에 남겨져 있으니 네트워크 트래픽이 줄어드는 것도 상당한 효과이다.
근데 실제 쿼리 로직 수행에 있어서는 그다지 차이는 없다고 한다.
사용자 정의 함수
SQL 함수를 우리가 직접 만들 수 있다!
프로시저랑 조금 비슷하면서도 다른 녀석.
이 녀석도 똑같이 정의는 하는데, 대신 이놈은 다른 select문에서 활용할 수 있다.
CREATE OR REPLACE FUNCTION F_GET_TK_GFF_CNT
(
IN_SUBWAY_STATN_NO IN TB_SUBWAY_STATN.SUBWAY_STATN_NO%TYPE
, IN_STD_YM IN TB_SUBWAY_STATN_TK_GFF.STD_YM %TYPE
)
-- 반환형을 명시한다.
RETURN NUMBER
-- 반환할 때 사용할 변수
IS
V_TK_GFF_CNT NUMBER;
BEGIN
SELECT SUM(A.TK_GFF_CNT) AS TK_GFF_CNT
INTO V_TK_GFF_CNT -- 반환값이 담기는 변수
FROM TB_SUBWAY_STATN_TK_GFF A
WHERE A.SUBWAY_STATN_NO = IN_SUBWAY_STATN_NO
AND A.STD_YM = IN_STD_YM
;
RETURN V_TK_GFF_CNT; -- 그 변수를 반환한다.
END;
/
이런 식으로 사용자 정의 함수를 만든다.
명확하게 반환 타입을 지정한다.
select into라는 신기한 문법이 보인다.
SELECT *
FROM
(
SELECT A.SUBWAY_STATN_NO, A.LN_NM, A.STATN_NM
, F_GET_TK_GFF_CNT(A.SUBWAY_STATN_NO, '202010') AS TK_GFF_CNT
FROM TB_SUBWAY_STATN A
WHERE A.LN_NM = '9호선'
ORDER BY TK_GFF_CNT DESC
)
WHERE ROWNUM <= 10
;
이렇게 인라인으로 쓸 수 있다!
내부에서 커밋, 롤백은 불가능하게 되어있다.
로직 분리도 잘 안 되고, 괜히 커밋이 되면 롤백도 힘들어지기 때문.
또한 기본적으로 return은 한 행만 가능하지만, record(일종의 자료형)를 미리 지정한 후에 여러 컬럼을 리턴할 수도 있다.
트리거
이것은 특정 테이블에 자동 수행되도록 dbms에다 설정해두는 함수이다.
그러니 이놈은 언제 트리거가 걸릴지를 명시해서 작성해야 한다.
CREATE OR REPLACE TRIGGER TRIG_TB_POPLTN_CTPRVN_INSERT
AFTER INSERT -- insert 발생한 후에 트리거 실행
ON TB_POPLTN -- 어떤 테이블에
FOR EACH ROW -- 각 행에 대해서
DECLARE
V_ADSTRD_CD TB_POPLTN.ADSTRD_CD%TYPE;
V_STD_YM TB_POPLTN.STD_YM%TYPE;
V_POPLTN_SE_CD TB_POPLTN.POPLTN_SE_CD%TYPE;
V_AGRDE_SE_CD TB_POPLTN.AGRDE_SE_CD%TYPE;
BEGIN
V_ADSTRD_CD := :NEW.ADSTRD_CD; --TB_POPLTN에 새로 들어온 adstrd_cd 값
V_STD_YM := :NEW.STD_YM;
V_POPLTN_SE_CD := :NEW.POPLTN_SE_CD;
V_AGRDE_SE_CD := :NEW.AGRDE_SE_CD;
UPDATE TB_POPLTN_CTPRVN A
SET A.POPLTN_CNT = A.POPLTN_CNT + :NEW.POPLTN_CNT
WHERE A.CTPRVN_CD = SUBSTR(V_ADSTRD_CD, 1, 2)
AND A.STD_YM = V_STD_YM
AND A.POPLTN_SE_CD = V_POPLTN_SE_CD
AND A.AGRDE_SE_CD = V_AGRDE_SE_CD
;
-- 만약 위 update가 동작하지 않으면 insert함.
-- if문은 해당하는 없는 상태가 될 때 충족되기에 위 구문 때문에 실행되는 것이다.
-- 이게 바로 UPSERT 직접 구현 편..
IF SQL%NOTFOUND THEN
INSERT INTO
TB_POPLTN_CTPRVN (
CTPRVN_CD
, CTPRVN_NM
, STD_YM
, POPLTN_SE_CD
, AGRDE_SE_CD
, POPLTN_CNT
)
VALUES (
SUBSTR(V_ADSTRD_CD, 1, 2)
, (SELECT L.ADRES_CL_NM
FROM TB_ADRES_CL L
WHERE L.ADRES_CL_CD = SUBSTR(V_ADSTRD_CD, 1, 2)
AND L.ADRES_CL_SE_CD = 'ACS001'
)
, V_STD_YM
, V_POPLTN_SE_CD
, V_AGRDE_SE_CD
, :NEW.POPLTN_CNT
);
END IF;
END;
점점 더 어지럽다.
초반 부분에 트리거 발동조건을 거는 것이 보인다.
그리고 삽입된 행 값은 NEW라는 이름의 변수 속에 담긴 것처럼 사용하고 있다.
for each row를 넣지 않으면 insert가 한번에 여러번 들어가도 한번만 실행되는 것이다.
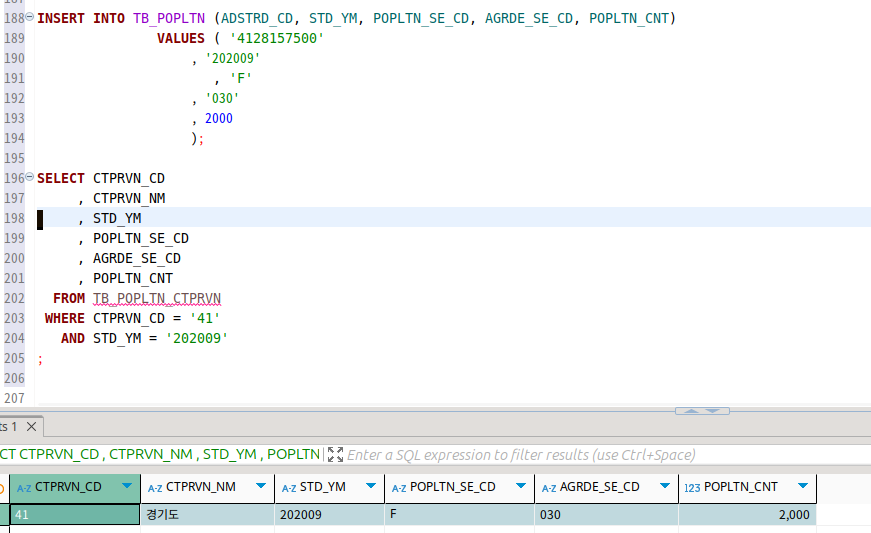
보다시피 insert 작업이 다른 테이블에 일어났는데 이쪽 테이블에 작업이 일어났다.
트리거 함수 내부에 커밋이 없으므로, 롤백을 때리면 두 테이블의 삽입이 다 날아간다.
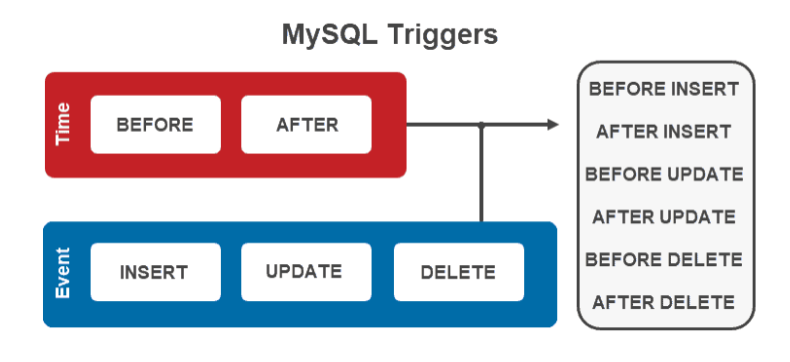
이렇게 트리거를 걸 수 있다.
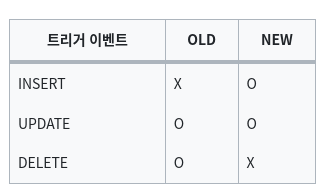
위에서 사용된 변수다.
insert를 할 때는 당연히 old 변수는 없다.
정리
현재 3개의 절차형 sql 방식을 배웠는데, 이 각각의 차이를 아는 것은 중요하다.
트리거는 자동으로 일어나고, 내부에서 커밋이나 롤백이 불가능하다.